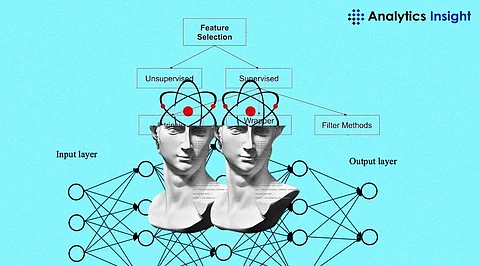

Feature selection methods for Regression Data are essential components of data analysis and science. By limiting the amount of input variables in a regression model to just the most informative ones, these techniques simplify the data. The model's performance is improved through this procedure, increasing its accuracy and efficiency.
The objective is to reduce the complexity of the model without compromising its predictive ability by choosing the features that have the greatest influence on the result prediction. These feature selection methods are vital in the analysis of Regression Data as they are critical in managing high-dimensional data.
To rank the features according to their significance and applicability to the target variable, this approach employs random forests.
To choose the optimal features, this technique takes the feature significance ratings from several machine learning algorithms, such as support vector machines, decision trees, and linear regression.
Through the use of a regularization approach, this strategy efficiently eliminates the less significant features from the model by penalizing the feature coefficients and shrinking them to zero.
Using a greedy search algorithm, this approach adds or eliminates features one at a time by a predetermined criterion, like the Bayesian information criterion (BIC) or the Akaike information criterion (AIC).
The relative contribution of each feature to the target variable is calculated using this technique by utilizing the standardized coefficients from a linear regression model.
Until the required number of features is obtained, this technique uses a wrapper approach to train a model repeatedly and delete the features with the lowest relevance scores.
To choose the ideal subset of characteristics that optimizes the performance of the model, this approach employs an optimization strategy inspired by biology and mimicking the process of natural selection.
Assuming that the characteristics with low variance have little to no predictive potential, this strategy eliminates them using an unsupervised technique.
This technique chooses the features with the greatest MAD values by using an unsupervised methodology to estimate the average absolute difference between each feature's values and its mean.
By calculating each feature's variance to mean ratio and choosing the features with the greatest DR values, this method employs an unsupervised technique.
Join our WhatsApp Channel to get the latest news, exclusives and videos on WhatsApp
_____________
Disclaimer: Analytics Insight does not provide financial advice or guidance on cryptocurrencies and stocks. Also note that the cryptocurrencies mentioned/listed on the website could potentially be risky, i.e. designed to induce you to invest financial resources that may be lost forever and not be recoverable once investments are made. This article is provided for informational purposes and does not constitute investment advice. You are responsible for conducting your own research (DYOR) before making any investments. Read more about the financial risks involved here.